Já ouviu falar sobre a regressão linear e está curioso para entender melhor sobre ela? Preparamos um material especialmente para você que não tem conhecimento na área de exatas (ou completamente leigo) e deseja compreender o que é essa técnica estatística sem a necessidade de fórmulas complexas.
O que é regressão linear?
A regressão linear é uma técnica estatística que nos ajuda a entender a relação entre duas variáveis. Quando temos duas variáveis, podemos querer saber se elas estão relacionadas entre si e, se estiverem, podemos querer entender essa relação para poder fazer previsões ou tomar decisões baseadas nos dados.
Por exemplo, se estivermos estudando o desempenho de alunos em uma escola, podemos querer saber se existe uma relação entre a quantidade de tempo que um aluno estuda e a nota que ele recebe em uma prova. Usando a regressão linear, podemos traçar uma linha que representa essa relação e prever qual seria a nota de um aluno com base na quantidade de tempo que ele estuda.
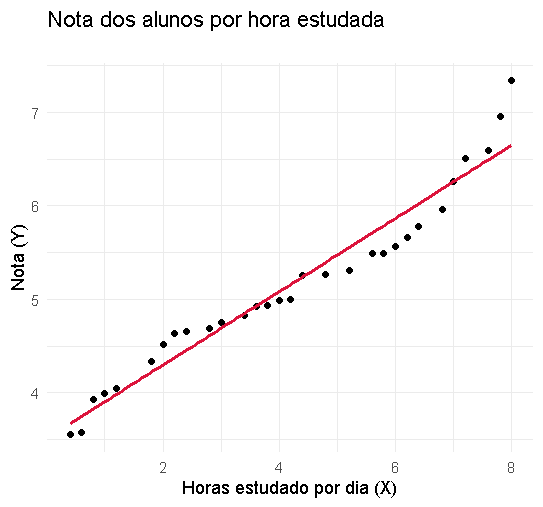
O objetivo da regressão linear é encontrar a melhor linha que representa a relação entre as duas variáveis. Essa linha é chamada de “linha de regressão” e é baseada nos dados que temos disponíveis. A linha de regressão é criada de forma que minimize a distância entre ela e os pontos de dados reais. Em outras palavras, a linha de regressão é criada para que se ajuste da melhor forma possível aos dados que temos.
Como funciona a regressão linear?
Para realizar uma análise de regressão linear, é necessário primeiramente definir qual é a variável dependente e quais são as variáveis independentes. Em seguida, é necessário coletar os dados e estimar os parâmetros da equação de regressão, ou seja, os coeficientes que multiplicam as variáveis independentes na equação.
O modelo de regressão linear simples é representado pela equação Y = a + bX, em que Y é a variável dependente, X é a variável independente, a é o intercepto da reta e b é o coeficiente angular da reta. O intercepto representa o valor de Y quando X é igual a zero, enquanto o coeficiente angular representa a variação esperada de Y para cada unidade de variação de X.
Para estimar os coeficientes da equação de regressão, é utilizada a técnica dos mínimos quadrados, que busca encontrar a reta que minimize a soma dos quadrados dos desvios entre os valores observados e os valores previstos pela equação. Uma vez estimados os coeficientes, é possível fazer previsões para valores futuros da variável dependente com base nos valores conhecidos das variáveis independentes.
É importante ressaltar que a regressão linear pode ser aplicada em modelos mais complexos que envolvem mais de uma variável independente, conhecidos como modelos de regressão linear múltipla. Nesses casos, a equação de regressão é representada por Y = a + b1X1 + b2X2 + … + bnXn, em que Xi representa a i-ésima variável independente e bi representa o coeficiente que multiplica essa variável na equação.
Como interpretar os resultados da regressão?
Ao usar a regressão linear, é importante interpretar os resultados corretamente. Um dos principais resultados que precisamos entender é o coeficiente de determinação (R²). O R² é um valor que varia de 0 a 1 e representa a proporção da variância na variável dependente que é explicada pela variável independente. Quanto maior o valor de R², melhor a regressão explica a relação entre as variáveis.
Por exemplo, se o R² for 0,95, isso significa que 95% da variação na variável dependente pode ser explicada pela variável independente. No entanto, é importante lembrar que o R² não indica causalidade e, portanto, é necessário interpretar os resultados com cuidado.
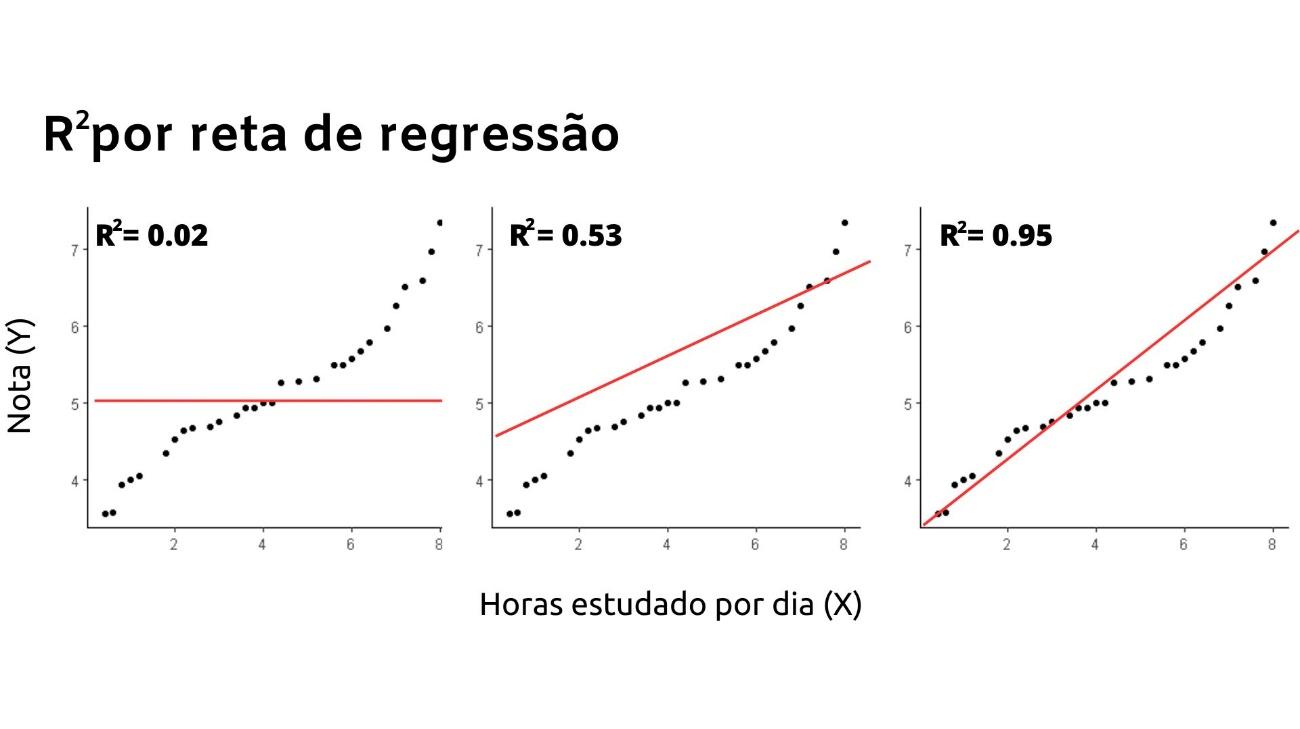
Embora a regressão linear seja uma técnica poderosa, ela tem suas limitações. A suposição de linearidade da regressão linear é um dos pressupostos mais importantes que devem ser verificados antes de se aplicar essa técnica. A linearidade implica que a relação entre as variáveis deve ser representada por uma linha reta. No entanto, muitas vezes a relação entre as variáveis pode não ser linear, apresentando curvas, desvios ou formas mais complexas. Nesses casos, a regressão linear pode não ser capaz de capturar a natureza não-linear da relação, resultando em uma modelagem inadequada e na obtenção de estimativas imprecisas ou viesadas.
Uma forma de lidar com a limitação da suposição de linearidade é por meio da utilização de técnicas de regressão não-linear, como a regressão polinomial ou a regressão logística. Essas técnicas permitem modelar relações mais complexas entre as variáveis, por meio de equações não-lineares. A regressão polinomial, por exemplo, pode ser utilizada para modelar relações quadráticas, cúbicas ou de ordem superior, enquanto a regressão logística é indicada para modelar relações binárias, onde a variável dependente é categórica.
Outra limitação da regressão linear é a presença de outliers, que são valores extremos que se distanciam significativamente dos demais valores da amostra. Os outliers podem afetar a estimação dos coeficientes da regressão, uma vez que a influência desses valores extremos pode ser muito grande. Uma forma de lidar com os outliers é por meio da utilização de técnicas de regressão robusta, como a regressão robusta para M-estimadores. Essa técnica é menos sensível aos outliers e pode fornecer estimativas mais precisas dos coeficientes da regressão mesmo em presença de valores extremos.
Em resumo, embora a regressão linear seja uma técnica estatística amplamente utilizada, é importante considerar suas limitações e verificar se a suposição de linearidade é adequada para o problema em questão. Além disso, é importante verificar a presença de outliers e considerar outras técnicas de regressão mais adequadas quando necessário, como a regressão não-linear ou a regressão robusta.
Aplicação
Voltando para o exemplo de tempo de estudo e nota. Suponha que um pesquisador queira investigar se existe uma relação linear entre essas duas variáveis, ou seja, se os alunos que estudam mais tendem a ter notas mais altas.
O pesquisador coleta os dados de uma amostra de 30 alunos e registra o tempo que cada um deles estudou para a prova e a nota que cada um obteve.
| Nota (Y) | Tempo (X) | Nota (Y) | Tempo (X) | Nota (Y) | Tempo (X) | ||
| 0.4 | 3.55 | 3.0 | 4.75 | 5.8 | 5.49 | ||
| 0.6 | 3.57 | 3.4 | 4.82 | 6.0 | 5.56 | ||
| 0.8 | 3.93 | 3.6 | 4.92 | 6.2 | 5.66 | ||
| 1.0 | 3.99 | 3.8 | 4.93 | 6.4 | 5.78 | ||
| 1.2 | 4.05 | 4.0 | 4.98 | 6.8 | 5.96 | ||
| 1.8 | 4.33 | 4.2 | 4.99 | 7.0 | 6.25 | ||
| 2.0 | 4.51 | 4.4 | 5.25 | 7.2 | 6.50 | ||
| 2.2 | 4.63 | 4.8 | 5.26 | 7.6 | 6.59 | ||
| 2.4 | 4.66 | 5.2 | 5.31 | 7.8 | 6.96 | ||
| 2.8 | 4.68 | 5.6 | 5.48 | 8.0 | 10 |
Em seguida, ele utiliza a técnica da regressão linear para estimar a equação da reta que melhor descreve a relação entre essas variáveis.
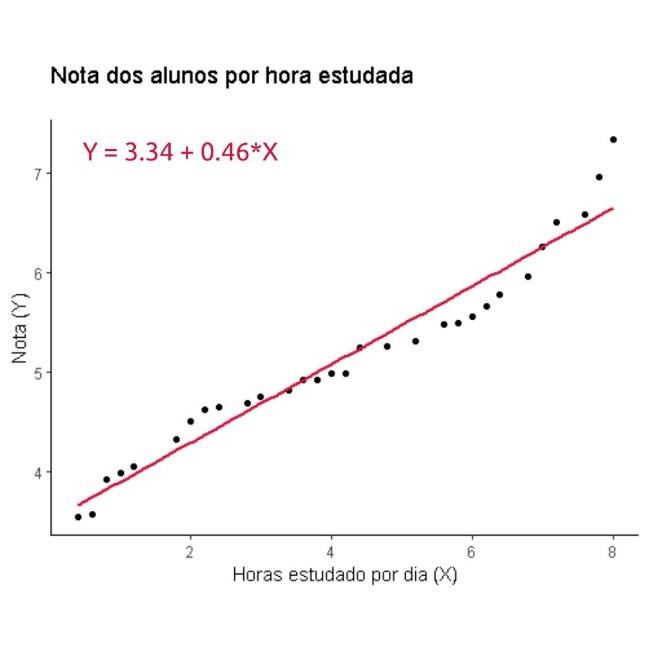
Temos que Y = 3.34 + 0.46X, onde Y representa a nota do aluno e X representa o tempo que ele estudou para a prova, o intercepto da reta (a = 3.34) indica que um aluno que não estudou teria uma nota esperada de 3.34 pontos, enquanto o coeficiente angular da reta (b = 0.46) indica que a cada hora adicional de estudo na semana, espera-se um acréscimo de 0.46 pontos na nota do aluno.
Com base nessa equação, é possível fazer previsões para valores futuros da variável dependente (a nota) com base nos valores conhecidos da variável independente (o tempo de estudo). Por exemplo, se um aluno estuda 5 horas para a próxima prova, a nota esperada seria de 5.64 pontos (3.34 + 0.46*5).
No entanto, é importante ressaltar que a relação entre o tempo de estudo e a nota pode não ser linear em toda a faixa de valores observados. Além disso, outros fatores que não foram incluídos na análise podem influenciar a nota do aluno, como a qualidade do material de estudo, a habilidade do aluno em lidar com provas e a presença de fatores externos que possam afetar o desempenho na prova. Para isso deve recorrer-se a uma regressão multivariada.
Texto por Jonathan Conde Perez.
0 comentário